
Sorry, this activity is currently hidden
Section outline
-
Introduction
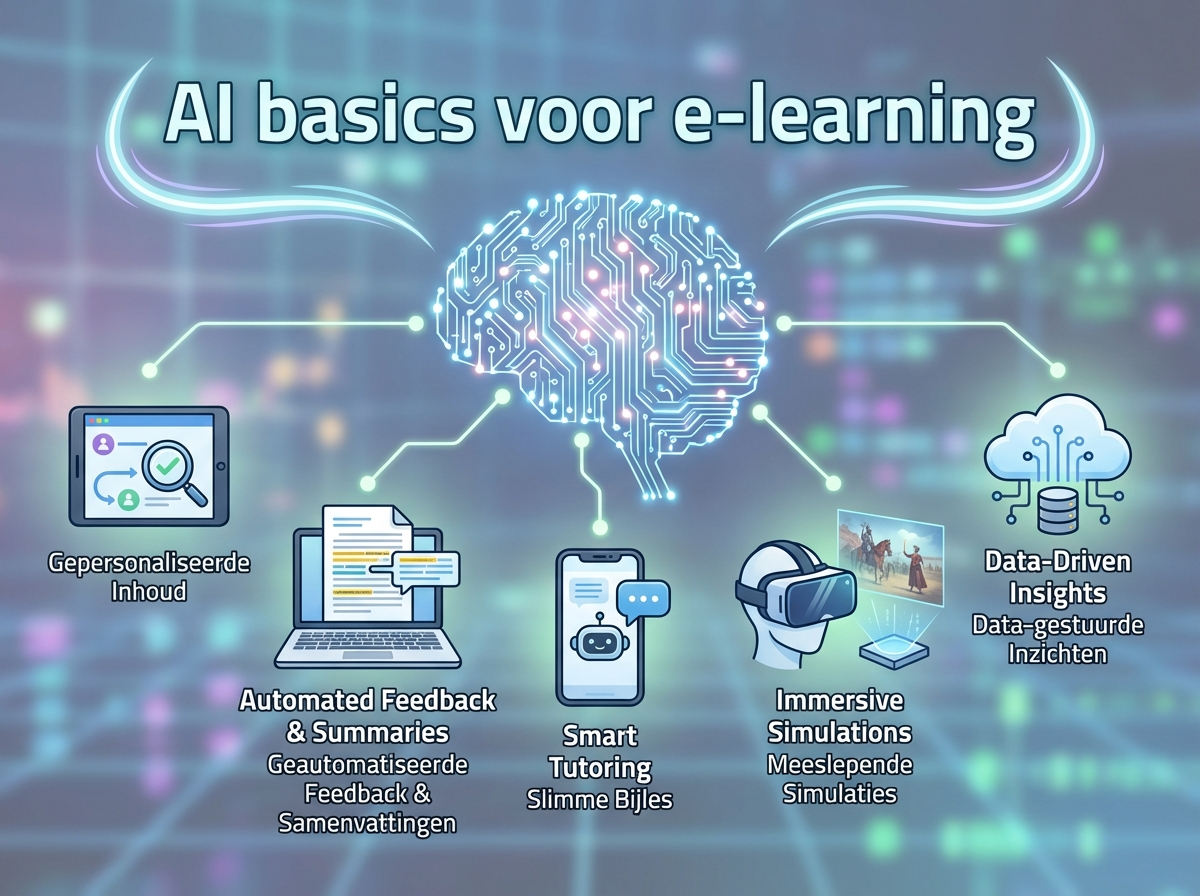
In deze sectie krijg je een helder basisbeeld van wat AI is en hoe je het praktisch inzet bij het maken van e-learnings. Als L&D-consultant of trainer helpt dit je om sneller te ontwerpen, varianten te genereren en kwaliteit te borgen zonder de didactiek uit het oog te verliezen. Je leert ook waar de grenzen liggen (zoals hallucinaties en juridische risico’s), zodat je AI verantwoord kunt toepassen.
Learning Objectives
-
Leg op hoofdlijnen uit wat AI-modellen doen en waarom hallucinaties kunnen ontstaan.
-
Benoem waar AI waarde toevoegt in het e-learningproces en kies passende tooltypen per use-case.
-
Schrijf een bruikbare promptstructuur en hanteer kwaliteitskaders om AI-output te beoordelen en te verbeteren.
-
-

Introduction
In deze afsluitende sectie verbind je alle kernconcepten uit de training tot een bruikbaar geheel voor je dagelijkse L&D- en trainerspraktijk. Je checkt of je de belangrijkste termen, keuzes en kwaliteitskaders beheerst en vertaalt dit naar concrete vervolgstappen. Zo rond je af met zekerheid over wat je al kunt toepassen en wat je als volgende wilt verdiepen.
Learning Objectives
-
Je vat de belangrijkste concepten en afspraken uit de training compact samen in eigen woorden.
-
Je identificeert je persoonlijke next steps om AI verantwoord en effectief te blijven inzetten in e-learningprojecten.
-