
Sorry, this activity is currently hidden
Section outline
-
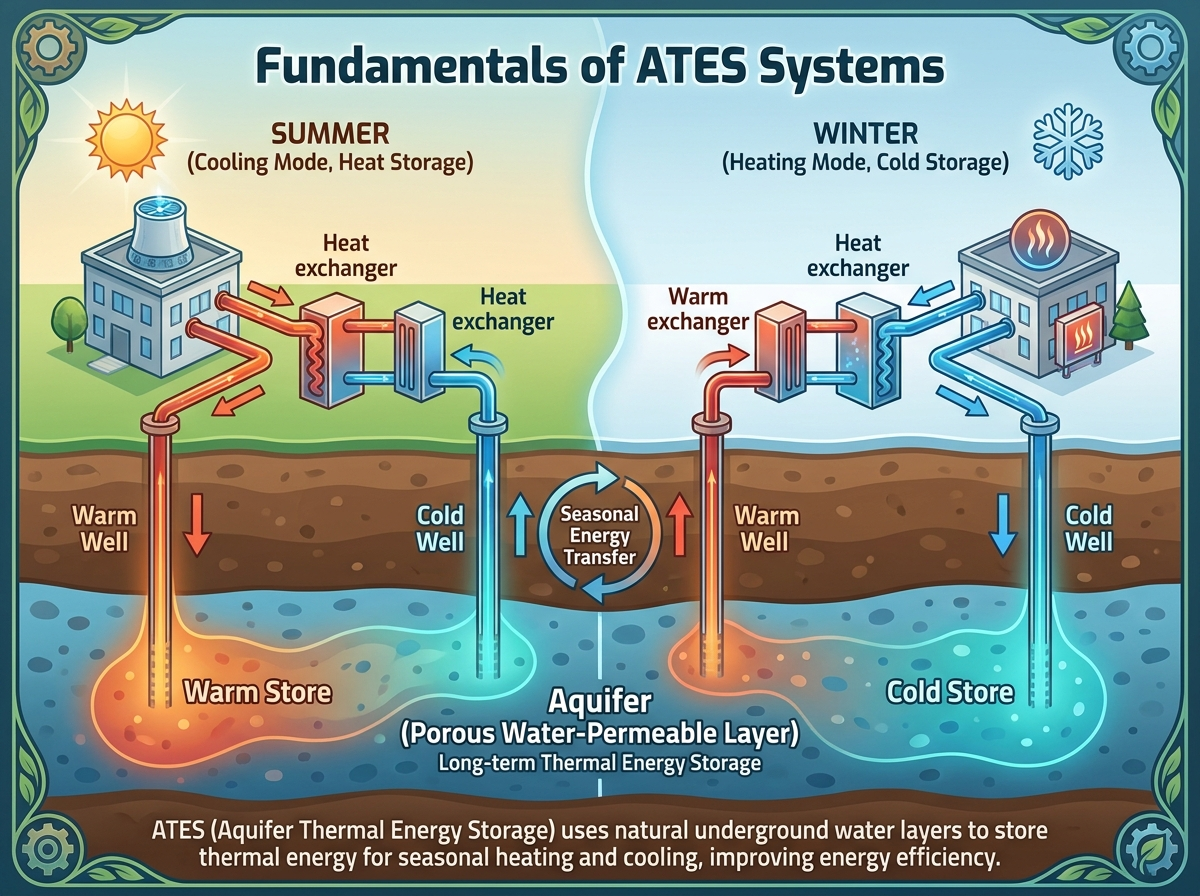
Introduction
This section builds a beginner-friendly foundation for understanding Aquifer Thermal Energy Storage (ATES) and why it matters in the ATES sector. You’ll learn what ATES is used for, how the main components fit together, and how seasonal charging and discharging work in plain language. It also positions ATES among other thermal storage options and highlights key concepts and beginner-level risks you’ll encounter in practice.
Learning Objectives
-
Explain what ATES is, including its purpose, benefits, and typical building or district energy use cases.
-
Identify the main ATES components and describe how they connect in a basic system layout.
-
Describe the seasonal operating principle of ATES, including warm/cold wells and charging vs. discharging cycles.
-
-
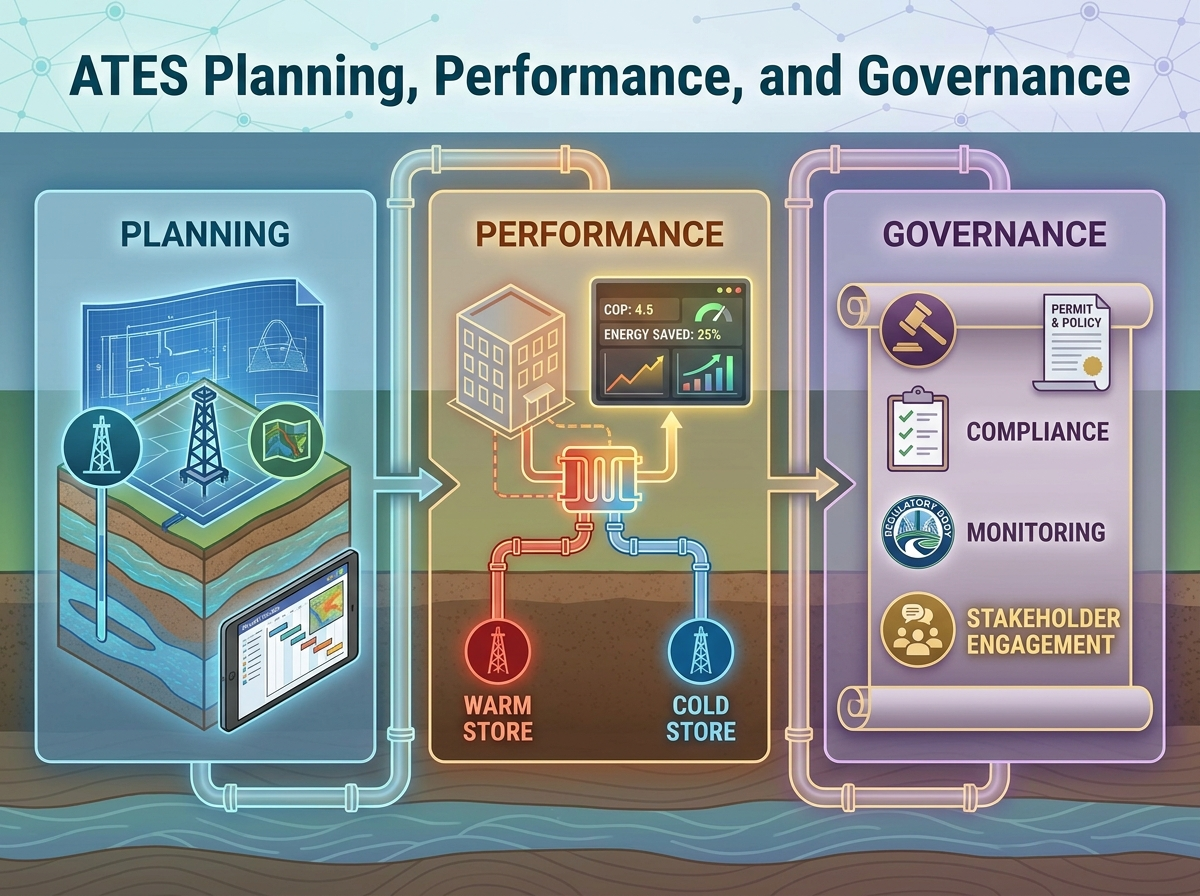
Introduction
This section focuses on the practical steps needed to plan an ATES system that performs reliably in real sites. You’ll learn how subsurface conditions, thermal–hydraulic behavior, and operational choices shape outcomes in the ATES sector. It also introduces the monitoring and governance basics that determine whether a project can be permitted, coordinated, and sustained over time.
Learning Objectives
-
Identify basic site suitability factors for ATES, including key aquifer and boundary conditions.
-
Explain how thermal and hydraulic interactions influence well spacing, plume behavior, and seasonal balance.
-
Select core monitoring measurements and recognize common failure modes and their typical symptoms.
-
-

Introduction
This section consolidates the essential beginner concepts covered across ATES fundamentals and planning considerations so you can see how the pieces fit together. You’ll reinforce the core language, system logic, and practical constraints that matter in real ATES projects. The goal is to leave with a coherent, end-to-end mental model before moving on to deeper design or governance topics.
Learning Objectives
-
Summarize the core ATES purpose, components, and operating cycle in clear, beginner-friendly terms.
-
Connect site/planning factors, performance drivers, and common risks into a single end-to-end ATES picture.
-
Identify personal knowledge gaps and define 2–3 next learning steps for continued ATES development.
-