
AI in de praktijk met PLTFRM
Section 1: Waarom mislukken AI-projecten — en wat werkt wel?
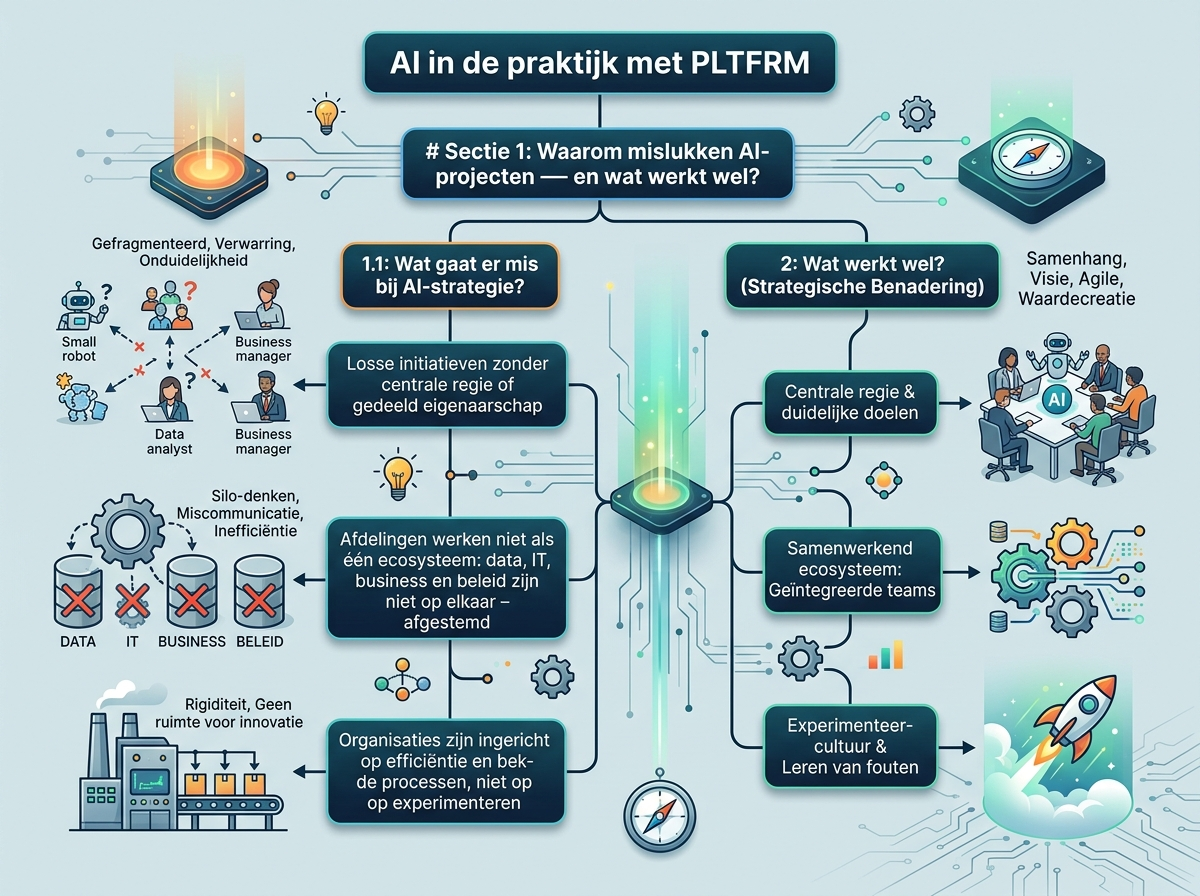
Lesson 1.1: Wat gaat er mis bij AI-strategie?
-
Losse initiatieven zonder centrale regie of gedeeld eigenaarschap
-
Afdelingen werken niet als één ecosysteem: data, IT, business en beleid zijn niet op elkaar afgestemd
-
Organisaties zijn ingericht op efficiëntie en bekende processen, niet op experimenteren
-
95% van AI-pilots slaagt er niet in aantoonbaar businesswaarde te genereren
-
Snelheid van AI-ontwikkeling maakt traditionele planningscycli ongeschikt
Lesson 1.2: Hoe bouw je een goede AI-strategie?
-
Werk iteratief en kortcyclisch; omarmen van experimenten is essentieel
-
Denk in drie assen: people, process en technology
-
Geef medewerkers kennis en ruimte om te experimenteren, ook zonder klaar beleid
-
Vermijd vendor lock-in door niet vast te pinnen op één model of leverancier
Lesson 1.3: AI embedding in de organisatie
-
Aparte AI-teams versus integratie binnen bestaande teams: beide met uitdagingen
-
Betrek techneuten, beleidsexperts en datamanagement; AI is geen IT-project alleen
-
Medewerkers die nu experimenteren zijn de digitale leiders van morgen
Lesson 1.4: Bijzonder gebruik: AI-agents voor strategiesimulatie
-
Agentic AI-model definieert marktpartijen als persona's
-
Simuleert meerdere rondes van argumentatie tussen persona's
-
Resultaat: onverwachte argumenten en emotieloos, neutraal simulatieproces
Section 2: Microsoft Copilot: van licentie naar echte adoptie
Lesson 2.1: Waarom kiezen bedrijven voor Copilot?
-
Al aanwezig in bestaande Microsoft 365-omgevingen
-
Data blijft binnen Europa, belangrijk voor datasoevereiniteit
-
Shadow AI tegengaan: voorkomen van gebruik gratis ChatGPT met bedrijfsdata
-
Compliance: alles blijft binnen dezelfde tenant
Lesson 2.2: Waar gaat het mis?
-
Licenties worden in bulk gekocht met onrealistische verwachtingen
-
Medewerkers ervaren dat het niet goed werkt, probleem zit in instellingen en prompting
-
Eén training gevolgd door stilte leidt tot gekelderd gebruik
Lesson 2.3: Hoe ziet een goed adoptietraject eruit?
-
Nulmeting via Microsoft's adoptiemonitoring
-
Refresher-sessies over mogelijkheden
-
Experimenteerfase van drie weken voor medewerkers
-
Gezamenlijke sessies om specifieke problemen op te lossen
-
Maandelijkse herhalingen gedurende een jaar
-
E-learning catalogus als naslagwerk
Lesson 2.4: Joiners, movers en doorlopend leren
-
Beleid helder vastleggen: toegestane tools en taken
-
Copilot verandert continu, medewerkers moeten bijblijven
-
Gebruik adoptiemonitoring om leerstrategieën aan te passen
Lesson 2.5: Copilot vs. andere AI-tools
-
Modellen achter Copilot, ChatGPT en Claude zijn grotendeels hetzelfde
-
Verschil zit in de gebruiksinterface en compliance
-
Productiviteitswinst ontstaat door combinatie met eigen bedrijfsdata
Section 3: Data als fundament voor AI
Lesson 3.1: Wat is data-kwaliteit en waarom begint het daarmee?
-
Data-kwaliteit betekent volledigheid, consistentie, actualiteit en bruikbaarheid
-
Onvolledige data leidt tot onbetrouwbare AI-uitkomsten (garbage in, garbage out)
-
Eerste stap: eerlijke inventarisatie van data en betrouwbaarheid
Lesson 3.2: Meest voorkomende dataproblemen
-
Data verspreid over meerdere niet-communicerende systemen
-
Inconsistente definities tussen afdelingen
-
Historische data bevat fouten, duplicaten en ontbrekende waarden
-
Rapportagedata is niet hetzelfde als AI-ready data
Lesson 3.3: De aanpak van DataGrow
-
Databronnen in kaart brengen en ontsluiten, ook uit legacy-systemen
-
Data samenvoegen via centraal dataplatform of cloud warehouse
-
Visualisatie via Power BI voor beslissers
-
Datastructuur AI-ready maken met labeling, structurering en kwaliteitscontrole
Lesson 3.4: Praktische handvatten
-
Begin klein met één databron of businessvraag die volledig klopt
-
Wees eerlijk over ontbrekende data als startpunt, niet als zwakte
-
Doorlooptijd varieert van weken tot maanden afhankelijk van systemen en kwaliteit
Section 4: AI-modellen: wanneer kies je wat?
Lesson 4.1: Standaard vs. maatwerk
-
Standaard tools zijn laagdrempelig en snel als startpunt
-
Maatwerk is nodig als standaard tools niet integreren met systemen
-
Maatwerk biedt minder bewegingsruimte maar minder foutmarge
-
Rol-specifieke agents zijn praktischer dan persoonsspecifieke agents
Lesson 4.2: Wat is een AI-agent?
-
Een taalmodel met mogelijkheid om acties uit te voeren
-
Essentieel om goede context mee te geven
-
80% van een agent bouwen gaat snel, laatste 20% is complex en productiewaardig
Lesson 4.3: Dataveiligheid en modelkeuze
-
Gratis accounts gebruiken data voor modeltraining, niet geschikt voor bedrijfsdata
-
Betaalde accounts gebruiken data niet voor training, voldoende voor meeste bedrijven
-
Kritieke partijen kiezen Europese open source modellen of zelf hosten
-
Zelf hosten geeft meer controle, maar hogere kosten en iets minder prestaties
Lesson 4.4: Van pilot naar implementatie
-
Proof of concept werkt voor bouwer, niet automatisch voor hele team
-
Identificeer early adopters en geef gerichte casus
-
Te brede doelstelling leidt tot vage AI-output; kies één specifiek domein en bewijs waarde